|
...making Linux just a little more fun! |
By Hiran Ramankutty |
Yacc ("Yet Another Compiler Compiler") is used to parse a language described by a context-free grammar. Not all context-free languages can be handled by Yacc or Bison and only those that are LALR(1) can be parsed. To be specific, this means that it must be possible to tell how to parse any portion of an input string with just a single token of look-ahead. I will explain that clearly later in this article.
Bison is also a parser generator in the style of Yacc. It was written primarily by Robert Corbett and Richard Stallman made it Yacc compatible. There are differences between Bison and Yacc, but that is not the purpose of this article.
Grammar can be associated with English language as a set of rules to construct meaningful sentences. We can say the same for context-free grammars. Almost all programming languages are based on context-free grammars. The set of rules in any grammar will deal with syntactic groupings that will help in the construction of semantic structures. To be specific, it means that we specify one or more syntactic groupings and give rules for constructing them from their parts. For example in C: `expression' is one kind of grouping. One rule for making an expression is, "An expression can be made of a minus sign and another expression". Another would be, "An expression is an integer". You must have noticed that the rules are recursive. In fact, every such grammar must then have a rule which leads out of the recursion.
The most common formal system for representing such rules is the Backus-Naur Form or "BNF". All BNF grammars are context-free grammars.
In the grammatical rules for a language, we name a grouping as a symbol. Those symbols which can be sub-divided into smaller constructs are called non-terminals and those which cannot be subdivided are called terminals. If a piece of input is a single terminal then it is called a token and if it is a single nonterminal it is called a grouping. For example: `identifier', `number', `string' are distinguished as tokens, Whereas `expression', `statement', `declaration' and `function definition' are groupings in C language. Now, the full grammar may use additional language constructs with another set of nonterminal symbols.
A parser for grammar G determines whether an input string say `w' is a sentence of G or not. If `w' is a sentence of G then the parser produces the parse tree for `w' otherwise, an error message is produced. By parse tree we mean a diagram that represents the syntactic structure of a string `w'. There are two basic types of parsers for context-free grammars - bottom-up and top-down, the former one being of our interest.
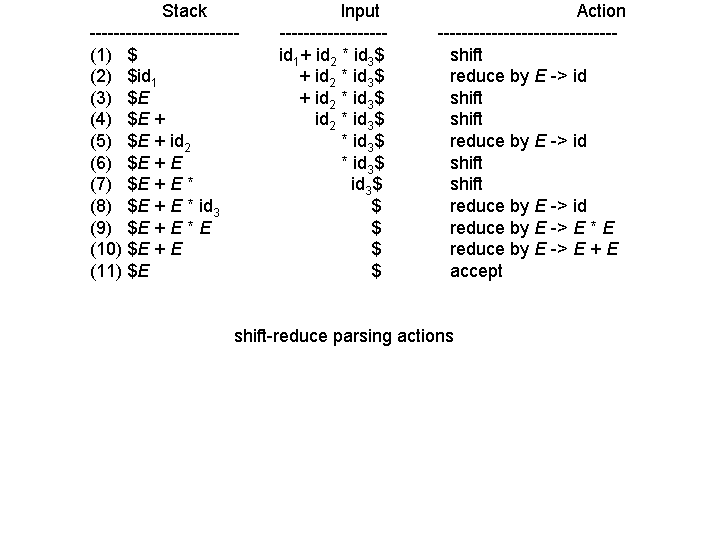
It is also known as Shift-Reduce Parsing. Here, attempts to construct a parse tree for an input begin at the leaves (bottom) and work up towards the root (top). In other words this will lead to a process of `reduction' of the input string to the start symbol of the grammar based on its production rules. For example, consider the grammar:
S -> aAcBe A -> Ab/b B -> d
Let w = "abbcde". Our aim is to reduce this string `w' to S, where S is the start symbol. We scan "abbcde" looking for substrings that match the right side of some production. The substrings `b' and `d' qualify. Again there are 2 b's to be considered. Let us proceed with leftmost `b'. We replace it by `A' the left side of the production A -> b. The string has now become "aAbcde". We now see that `Ab', `b' and `d' each match the right side of some production. This time we will choose to replace `Ab' by `A', the left side of the production A -> Ab. The string now becomes "aAcde". Then replacing `d' by `B', the left side of the production B -> d, we obtain "aAcBe". The entire string can now be replaced by S.
Basically, we are replacing the right side of a production by the left side the process being called a reduction. Quite easy! Not always. It sometimes so happen that, the substring that we choose to reduce may produce a string which is not decomposable to the start symbol S.
The substrings that are the right side of a production and when replaced with the left side of that production in the input string that leads eventually to the start symbol is called a `handle'. Now, the process of bottom-up parsing may be viewed as one of finding and reducing `handles', the reduction sequence being known as `handle pruning'.A convenient way to implement a shift-reduce parser is to use a stack and an input buffer. Let `$' symbol mark the bottom of the stack and the right end of the input.
The main concept is to shift the input symbols onto the stack until a handle b is on top of the stack. Now we reduce b to the left side of the appropriate production. The parser repeats this cycle until it has detected an error or until the stack contains the start symbol and the input is empty:
In fact, there are four possible actions that a shift-reduce parser can make and they are;
Let us see how these concepts are put into action in the example below.
Consider the grammar below:
E -> E + E E -> E * E E -> (E) E -> id
Let the input string be id1 + id2 * id3
The bottom-up tree construction process has two aspects.
Construction of LALR parser requires the basic understanding of constructing an LR parser. LR parser gets its name because it scans the input from left-to-right and constructs a rightmost derivation in reverse.
A parser generates a parsing table for a grammar. The parsing table consists of two parts, a parsing action function ACTION and a goto function GOTO.
An LR parser has an input, a stack, and a parsing table. The input is read from left to right, one symbol at a time. The stack contains a string of the form s0X1s1...Xmsm where sm is on top. Each Xi is a grammar symbol and each si is a symbol called a state. Each state symbol summarizes the information contained in the stack below it and is used to guide the shift-reduce decision.
The function ACTION stores values for sm that is topmost stack element and ai that is the current input symbol. The entry ACTION[sm, ai] can have one of four values:
The function GOTO takes a state and grammar symbol as arguments and produces a state. Somewhat analogous to the transition table of a deterministic finite automaton whose input symbols are the terminals and nonterminals of the grammar.
A configuration of an LR parser is a pair whose first component is the stack contents and whose second component is the unexpended input:
(s0 X1 s1 . . . Xm sm, ai ai+1 . . . an$)
The next move of the parser is determined by reading ai, the current input symbol, and sm the state on top of the stack, and then consulting the action table entry ACTION[sm, ai]. The four value mentioned above for action table entry will produce four different configurations as follows:
(s0 X1 s1 . . . Xm sm ai s, ai+1 . . . an$)
Here the configuration has shifted the current input symbol ai and the next state s = GOTO[sm, ai] onto the stack; ai+1 becomes the new current input symbol.(s0 X1 s1 . . . Xm-r sm-r A s, ai ai+1 . . . an$)
where s = GOTO[sm-r, A] and r is the length of B, the right side of the production. Here the first popped 2r symbols off the stack (r state symbols and r grammar symbols), exposing state sm-r. The parser then pushed both A, the left side of the production, and s, the entry for ACTION[sm-r, A], onto the stack. The current input symbol is not changed in a reduce move. Specifically, Xm-r+1 . . . Xm, the sequence of grammar symbols are popped off the stack and will always match B, the right side of the reducing production.The LR parsing algorithm is simple. Initially the LR parser is in the configuration (s0, a1a2...an$) where s0 is a designated intial state and a1a2...an is the string to be parsed. Then the parser executes moves until an accept or error action is encountered.
I mentioned earlier that the GOTO function is essentially the transition table of a deterministic finite automaton whose input symbols (terminals and nonterminals) and a state when taken as arguments produce another state. Hence the GOTO function can be represented by a graph (directed) like scheme, where each node or state will be a set of items with elements that are productions in the grammar. The elements comprise the core of the items. The edges representing the transition will be labeled with the symbol for which the transition from one state to another is predetermined.
In the LALR (lookahead-LR) technique, LR items with common core are coalesced, and the parsing actions are determined on the basis of the new GOTO function generated. The tables obtained are considerably smaller than the LR tables, yet most common syntactic constructs of programming languages can be expressed conveniently by LALR grammar.
I am not going deep into construction of tables. Instead, I would like to explain the use of a tool called Yacc for parser generation.
Input to Yacc can be divided into three sections:
We shall illustrate that by designing a small calculator that can add and subtract numbers. Let us start with the definitions section for the Yacc input file:
/* File name - calc1.l*/
%{
#include "y.tab.h"
#include < stdlib.h >
void yyerror(char *);
}%
%%
[0-9]+ {
yylval = atoi(yytext);
return INTEGER;
}
[-+\n] {
return *yytext;
}
[ \t] ; /*skip whitespace*/
. yyerror("Unknown character");
%%
int yywrap(void) {
return 1;
}
Yacc when run generates a parser in the file y.tab.c, along side which another file y.tab.h is also generated. Lex includes this file and utilizes the definitions for token values. Lex returns the values associated with the tokens in variable yylval. But to get tokens, yacc calls yylex the return value of which is integer.
The yacc input specification is given below:
/* file name calc1.y */
%{
int yylex(void);
void yyerror(char *);
%}
%token INTEGER
%%
program:
program expr '\n' { printf("%d\n", $2); }
|
;
expr:
INTEGER
| expr '+' expr { $$ = $1 + $3; }
| expr '-' expr { $$ = $1 - $3; }
;
%%
void yyerror(char *s) {
fprintf(stderr, "%s\n", s);
}
int main(void) {
yyparse();
return 0;
}
Here, the grammar is specified using productions. Left hand side of a production being a non terminal followed by a colon and then the right hand side of a production. The contents of the braces show the action associated with the productions. So what does the rules say ?
It says that a program consists of zero or more expressions. Each expression terminates with a newline. When a newline is detected, we print the value of the expression.
Now execute yacc as shown:
yacc -d calc1.l
You get a message "shift/reduce conflict". Shift/reduce conflict arises when the grammar is ambiguous and there is a possibility of more than one derivation tree. To understand this, consider the example given in the stack implementation of shift-reduce parsing. In step 6, instead of shifting we could have reduced appropriately as per the grammar . Then addition will have higher precedence over multiplication.
Before proceeding you must know about another kind of conflict that is reduce-reduce conflict. This arises when there are more than one option for reducing a stack symbol. For example: In the grammar below id can be reduced to T or E.
E -> T E -> id T -> id
Yacc takes a default action when conflicts arise. When there is shift-reduce conflict, yacc will shift and when there is reduce-reduce conflict, it will use the first rule in the listing. Yacc also issues a warning message when conflicts arise. Warnings can be eliminated by making the grammar unambiguous.
Coming back, yacc produces two files; y.tab.c and y.tab.h. Some lines one has to notice are:
#ifndef YYSTYPE typedef int YYSTYPE #endif #define INTEGER 257 YYSTYPE yylval
Internally, yacc maintains two stacks in memory; a parse stack and a value stack. The current parsing state is determined by the terminals and/or non terminals that are present in the parse stack. The value stack is always synchronized and holds an array of YYSTYPE elements, which associates a value with each element in the parse stack. So for example, when lex returns an INTEGER token, yacc shifts this token to the parse stack. At the same time, the corresponding yylval is shifted to the value stack. This makes it easier in finding the value of a token at any given time.
So when we apply the rule
expr: expr '+' expr { $$ = $1 + $3; }
we pop "expr '+' expr" and replace it by "expr". In other words we replace the right hand side of a production by left hand side of the same production. Here we pop three terms off the stack and push back one term. The value stack will contain "$1" for the first term on the right-hand side of the production, "$2" for the second and so on. "$$" designates the top of the stack after reduction has taken place. The above action adds the values associated with two expressions, pops three terms off the value stack, and pushes back a single sum. Thus the two stacks remain synchronized and when a newline is encountered, the value associated with expr is printed.
The last function that we need is a 'main'. But the grammar is ambiguous and yacc will issue shift-reduce warnings and will process the grammar using shift as the default operation.
I am not giving the function here because there is more to learn. I shall come up with that in the next part. I shall also explain how to remove ambiguity from the grammar and then design the calculator for it. In fact, some more funcionalities shall be incorporated into the grammar to have a better understanding.
![[BIO]](../gx/2002/note.png) I am a final year student of Computer Science at Government Engineering
College, Trichur, Kerala, India. Apart from Linux I enjoy reading books
on theoretical physics.
I am a final year student of Computer Science at Government Engineering
College, Trichur, Kerala, India. Apart from Linux I enjoy reading books
on theoretical physics.
{kind=link}